智东西全国十大配资
智东西全国十大配资
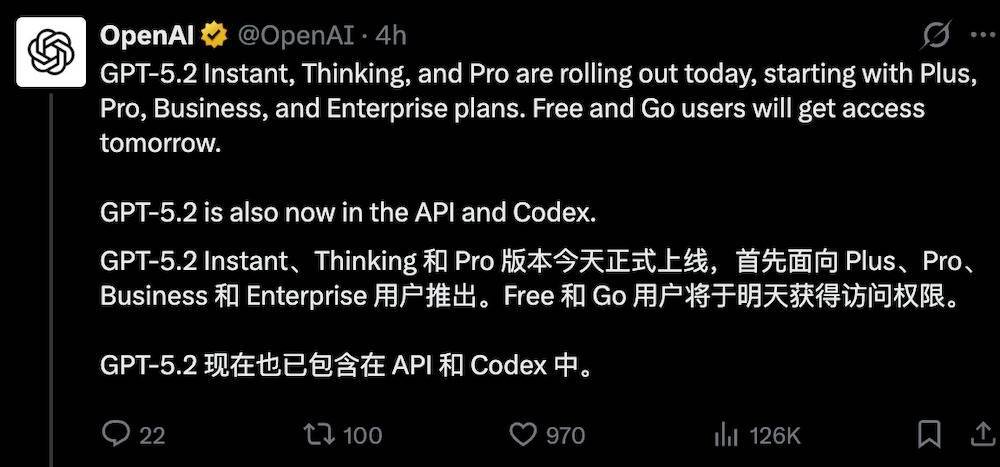
智东西12月12日报道,今日凌晨,正值OpenAI十周年生日,OpenAI正式推出其迄今最强模型GPT-5.2,并同步上线ChatGPT与API体系。
本次更新包含GPT-5.2 Instant、Thinking与Pro三个版本,将从今日起陆续向Plus、Pro、Business与Enterprise等付费方案用户开放,Free与Go用户预计将于明日获得访问权限。同时,GPT-5.2也已纳入API与Codex中供开发者调用。
▲图源:X平台
现有的GPT-5.1将在ChatGPT中继续作为过渡版本向付费用户提供三个月,之后将正式下线。OpenAI官方称,GPT-5.2属于其持续改进模型系列的一部分,后续仍将围绕过度拒绝、响应延迟等已知问题进行迭代优化。
在API端,GPT-5.2 Thinking对应gpt-5.2,Instant对应gpt-5.2-chat-latest,Pro对应gpt-5.2-pro,开发者可直接调用。

▲图源:OpenAI官方博客
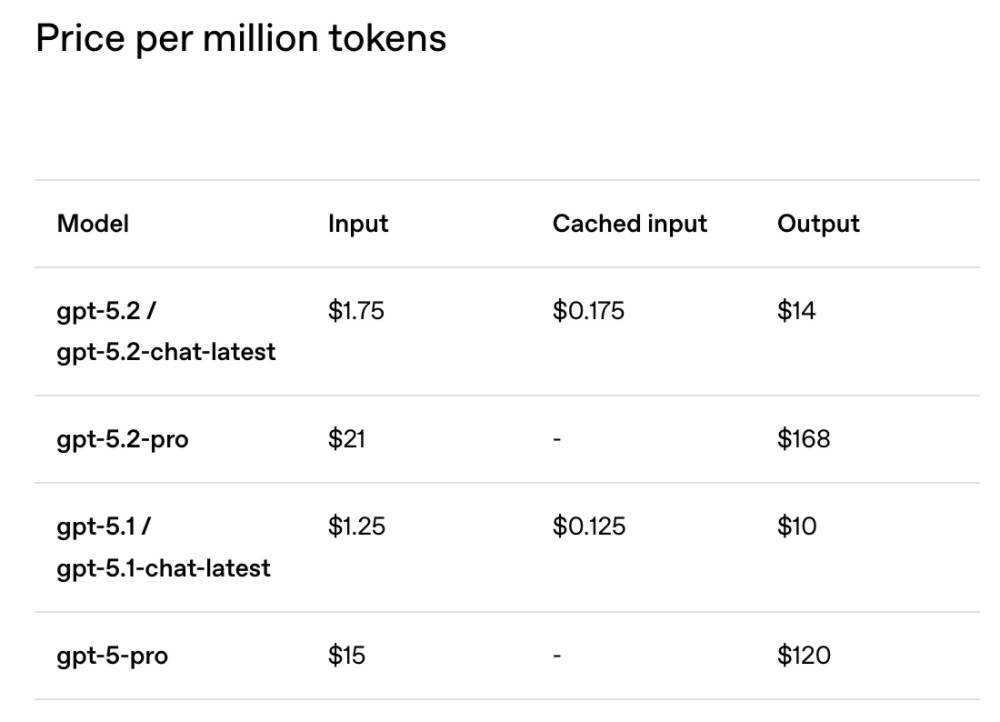
在价格方面,GPT-5.2的调用价格较上一代上调,输入端1.75美元/百万tokens(约合人民币12.35元/百万tokens)、输出端14美元/百万tokens(约合人民币98.81元/百万tokens)。GPT-5.2 Pro的定价为21美元与168美元/百万tokens(约合人民币148元与1185元/百万tokens),并首次支持第五档推理强度xhigh。
▲图源:OpenAI官方博客
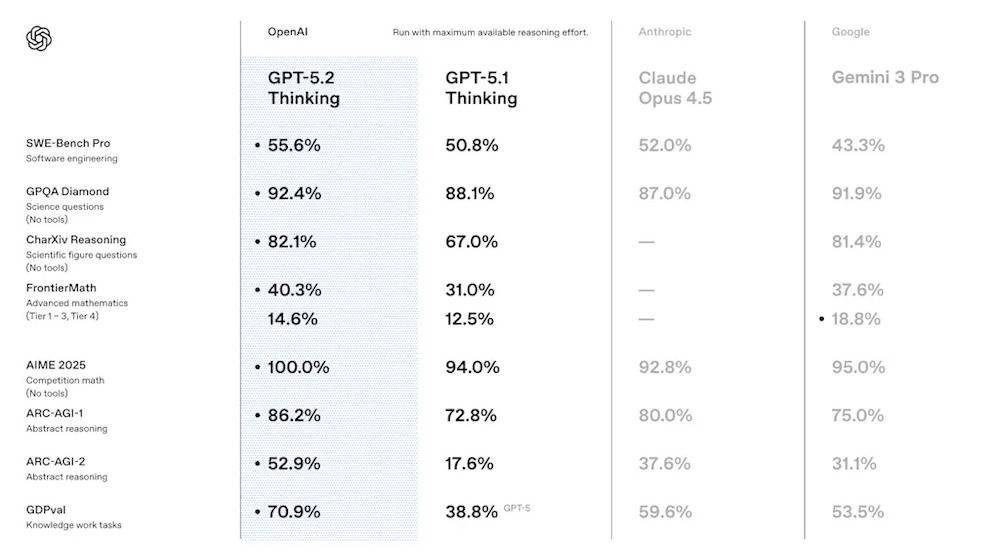
OpenAI联合创始人兼CEO Sam Altman在社交平台X上公布了GPT-5.2在多项前沿基准上的成绩:SWE-Bench Pro达到55.6%,ARC-AGI-2为52.9%,Frontier Math为40.3%。

▲图源:X平台
这些基准主要用于衡量模型在复杂代码修复、通用推理与高难度数学任务中的表现,GPT-5.2在高阶任务上的稳定性进一步提升。
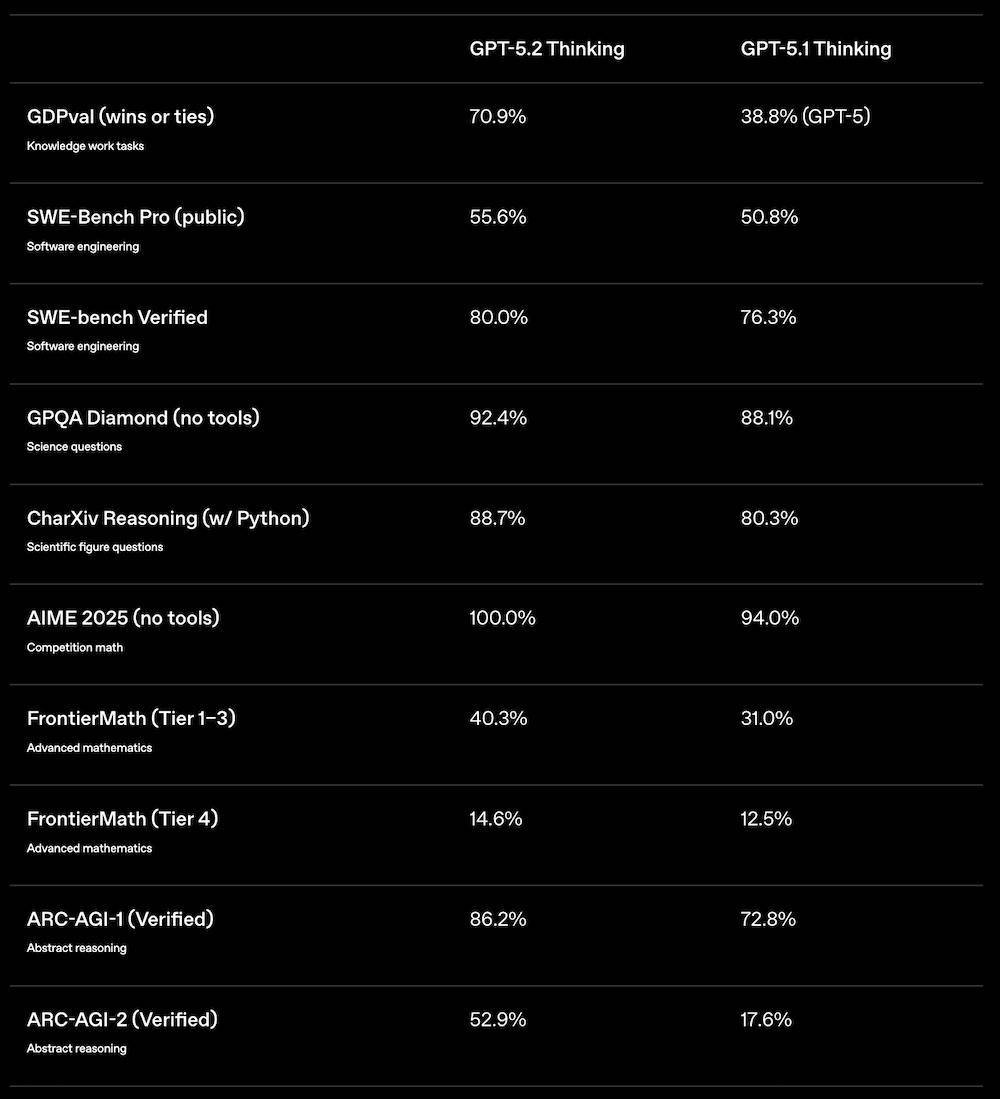
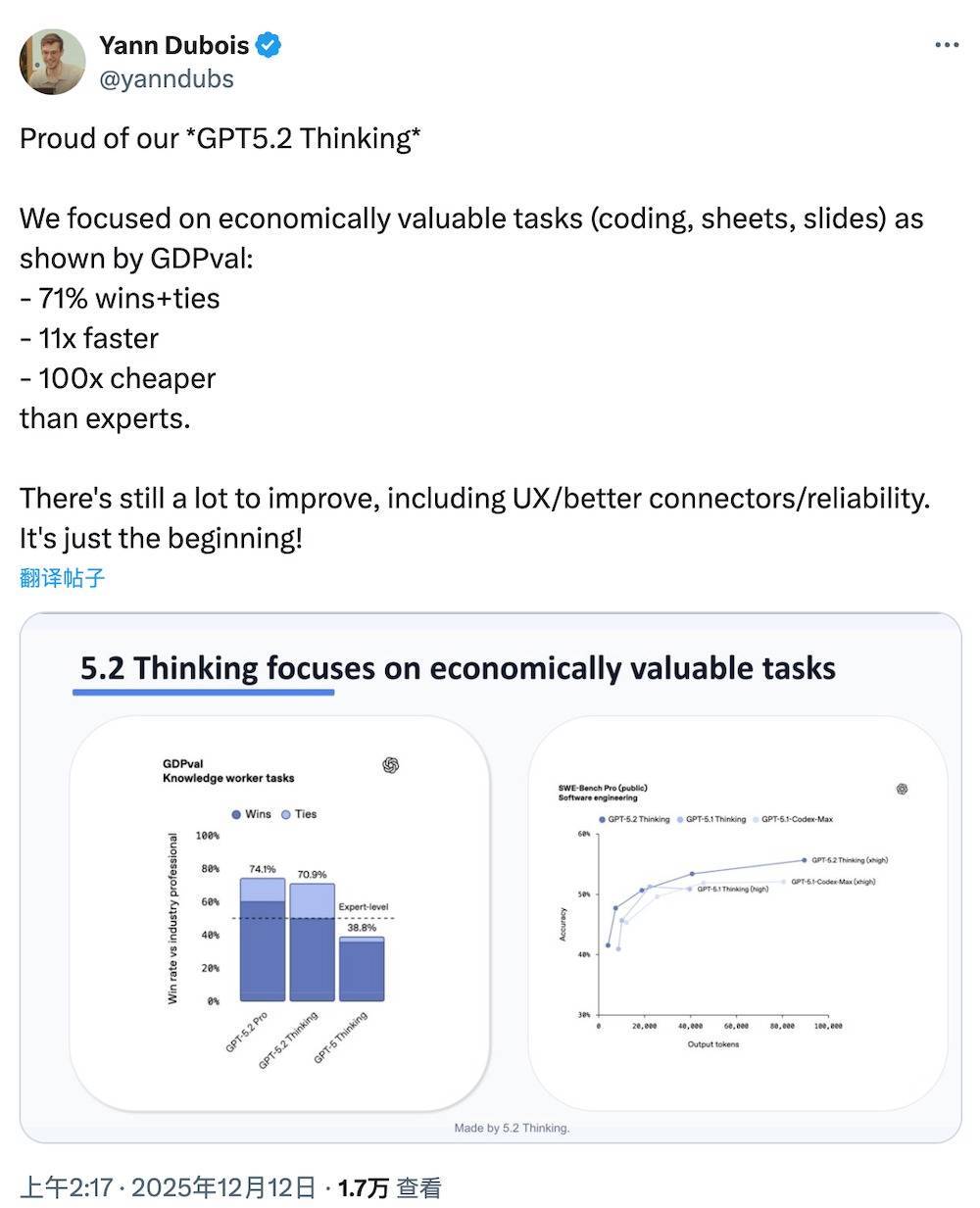
根据OpenAI官方博客,GPT-5.2在涵盖44个职业的明确知识工作任务中,表现均优于行业专业人士。相比GPT-5.1 Thinking,GPT-5.2 Thinking在应对知识型任务、编程、科学问题、数学、抽象推理的多项能力均大幅提升,尤其是在顶尖数学竞赛AIME 2025拿到满分成绩,在OpenAI专业工作基准测试GDPval中战胜或打平70.9%的人类专家。
▲图源:OpenAI官方博客
OpenAI团队成员Yann Dubois也在社交平台X平台上发帖称,GPT-5.2 Thinking的设计重点放在“经济价值较高的任务”(如编码、表格与演示文档)。
▲图源:X平台
此外,在SWE-Bench Pro、GPQA Diamond等8项基准测试中,GPT-5.2 Thinking的分数均超过谷歌Gemini 3 Pro和Anthropic Claude Opus 4.5。
▲图源:OpenAI
值得一提的是,GPT-5.2在处理多模态任务方面的能力明显提升,大有追上Gemini的架势,“顶流”AI编程助手Cursor第一时间宣布上新GPT-5.2。
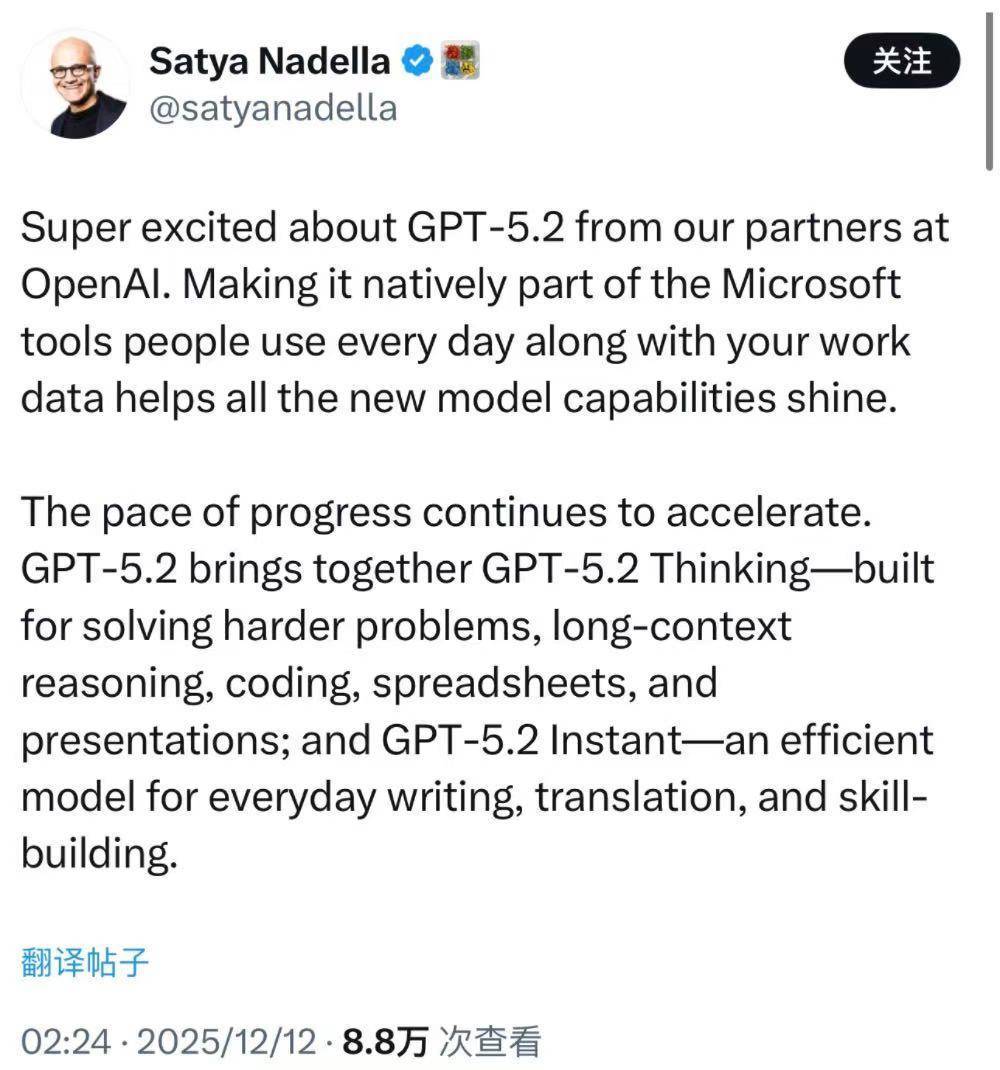
与此同时,微软董事长兼CEO Satya Nadella宣布,GPT-5.2将全面进入Microsoft 365 Copilot、GitHub Copilot与Foundry等产品体系。
▲图源:X平台
在GPT-5.2的发布会上,OpenAI应用业务负责人Fidji Simo也确认,外界关注已久的ChatGPT“成人模式(adult mode)”预计将在2026年第一季度上线。Fidji Simo称,在推出该模式前,OpenAI希望确保年龄预测模型足够成熟,能够准确识别未成年用户,同时避免误判成年人。
目前,该年龄预测模型已在部分国家进行早期测试,主要用于自动应用不同的内容限制与安全策略。
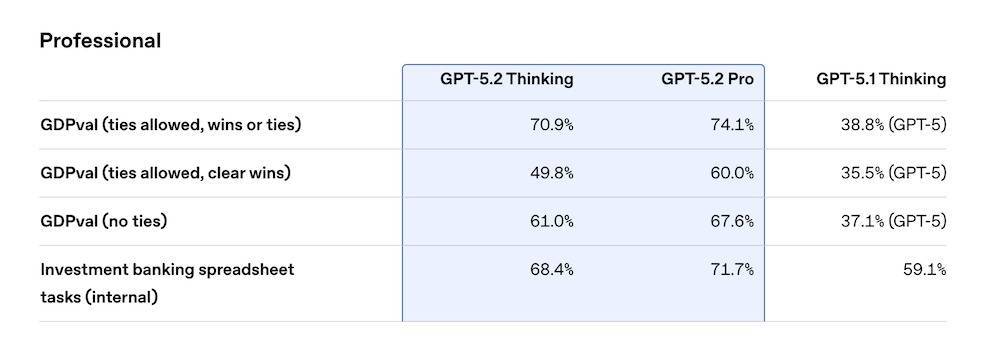
一、专业任务能力跃升,首次达到“专家级”评分根据OpenAI官方披露,GPT-5.2 Thinking在覆盖44类职业任务的GDPval评测中,首次达到“专家级”表现——在70.9%的对比中战胜或持平行业专业人士。GPT-5.2 Pro进一步提升至74.1%。在仅统计“明确胜出”的任务中,GPT-5.2 Thinking为49.8%,Pro则达到60%。
这一评测覆盖销售演示、预算模型、运营排班、制造流程图等多类真实业务成果。GPT-5.2在这些任务的生成速度约为人工专家的11倍,成本为其1%以下。
在投研类任务中,GPT-5.2 Thinking在内部评测的投行三表模型与杠杆收购模型等场景中的平均得分为68.4%,较GPT-5.1 Thinking的59.1%有明确提升,GPT-5.2 Pro得分进一步增长至71.7%。
▲图源:OpenAI官方博客
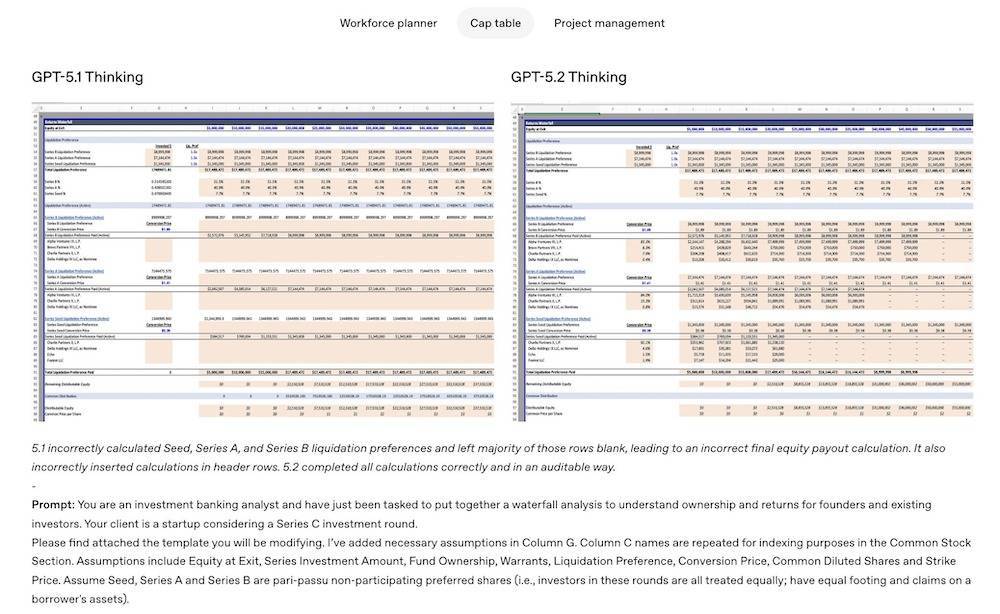
▲GPT-5.1 Thinking与GPT-5.2 Thinking效果对比
二、代码、工具调用与长链路任务全面升级在代码能力方面,GPT-5.2 Thinking在更严格的SWE-bench Pro(跨四种语言、强调真实工程难度)中取得55.6%,在SWE-bench Verified中更是达到80%,均显著领先GPT-5.1的50.8%与76.3%。在SWE-Lancer IC Diamond任务中,GPT-5.2 Thinking取得74.6%(GPT-5.1为69.7%)。
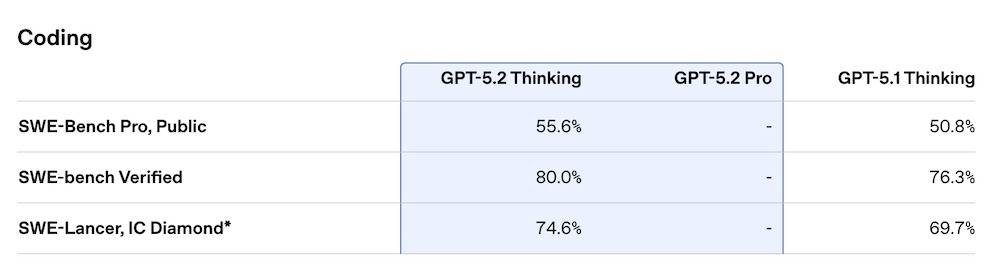
▲图源:OpenAI官方博客
与此同时,GPT-5.2出现在AI基准平台Imarena.ai(Arena)排行榜中,并在WebDev测试中取得1486分,位列第二,仅落后榜首3分,领先Claude-opus-4-5与Gemini-3-pro等主流模型。另一个版本GPT-5.2则以1399分排在第六。
根据Arena说明,GPT-5.2此前在内部以“robin”和“robin-high”为代号进行测试,其分数与GPT-5-medium仅相差1分,目前仍为初步结果,未来有望随着测试量积累而进一步稳定。
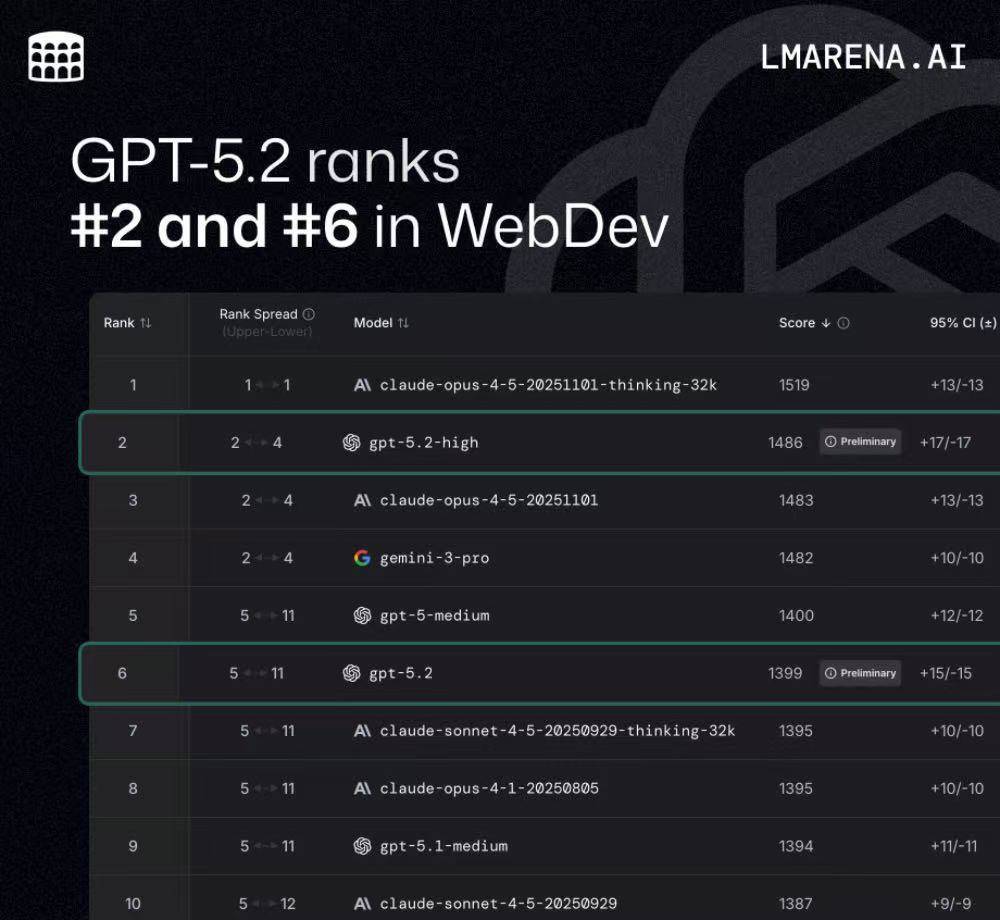
从评测维度来看,Arena主要衡量模型在可部署Web应用情境下的端到端编码能力,GPT-5.2已反映出其在复杂任务链条上的实用性。
在事实准确性方面,GPT-5.2 Thinking在基于ChatGPT查询的无错误回答率(开启搜索模式下)达到93.9%,较GPT-5.1的91.2%有所改善,在无搜索情况下也从87.3%提升至88%。
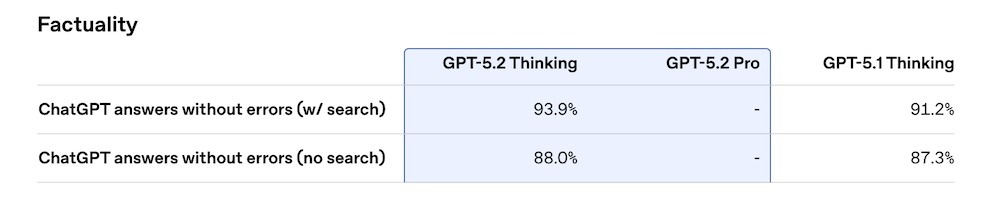
▲图源:OpenAI官方博客
另一个关键变化来自工具调用与长链路任务的可靠性提升。
GPT-5.2 Thinking在Tau-2 Bench Telecom中达到98.7%的最高得分,在零推理模式下也大幅领先上一代,在更高噪声的Retail场景中准确率从77.9%提升至82%。在更通用的工具链评估BrowseComp中,GPT-5.2 Thinking达到65.8%,Pro版本达到77.9%,亦高于GPT-5.1的50.8%。
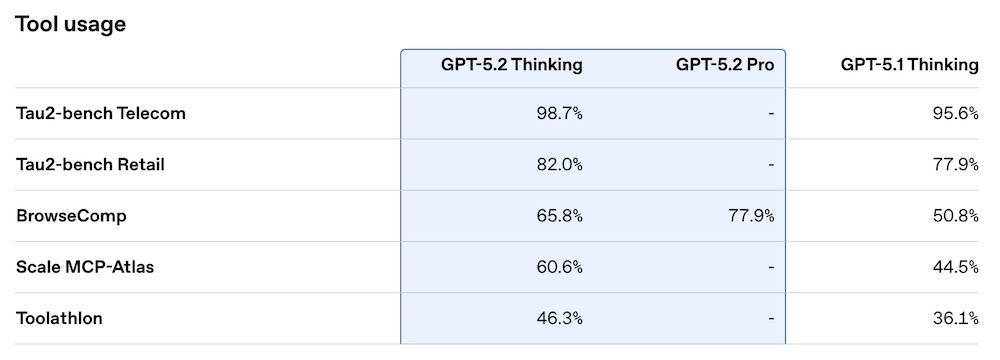
▲图源:OpenAI官方博客
OpenAI提到,GPT-5.2 Thinking和Pro均支持第五档推理强度xhigh,适用于长流程、多步骤、高精度的专业任务场景。
三、在长上下文与视觉理解,GPT-5.2全面增强在长上下文能力上,GPT-5.2 Thinking在OpenAI MRCRv2中全面领先上一代,在8 needles测试中从4k到256k的范围内均保持远高于GPT-5.1的表现,其中在4k–8k长度下达98.2%,在128k–256k长度下仍保持77.0%,而GPT-5.1同期为29.6%–47.8%区间。
在其他长文场景中,BrowseComp Long Context(128k/256k)中,GPT-5.2 Thinking分别达到92.0%与89.8%。GraphWalks任务中,GPT-5.2 Thinking在bfs与parents子集分别达到94.0%与89.0%,相比GPT-5.1的76.8%与71.5%显著提升。
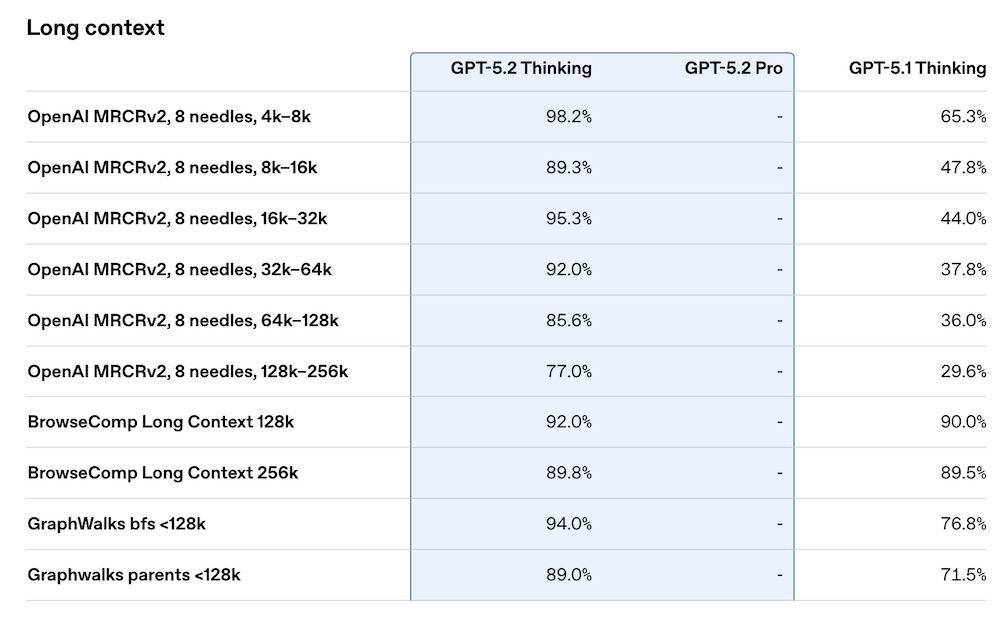
▲图源:OpenAI官方博客
在视觉理解上,GPT-5.2 Thinking在CharXiv科学图表推理任务中无工具模式下为82.1%,开启Python工具后进一步提升至88.7%。在ScreenSpot-Pro界面理解中,GPT-5.2 Thinking取得86.3%,远高于GPT-5.1的64.2%。在视频类、多模态综合难度更高的Video MMMU中,也从82.9%提升至85.9%。
在视觉能力上,GPT-5.2在ScreenSpot-Pro(界面理解)中达到86.3%的准确率,相比GPT-5.1有明显提升。在CharXiv科学图表推理任务中,也实现了准确率的大幅增长。这使其在处理科研图表、运营仪表盘、产品界面截图等专业视觉输入时更加可靠。
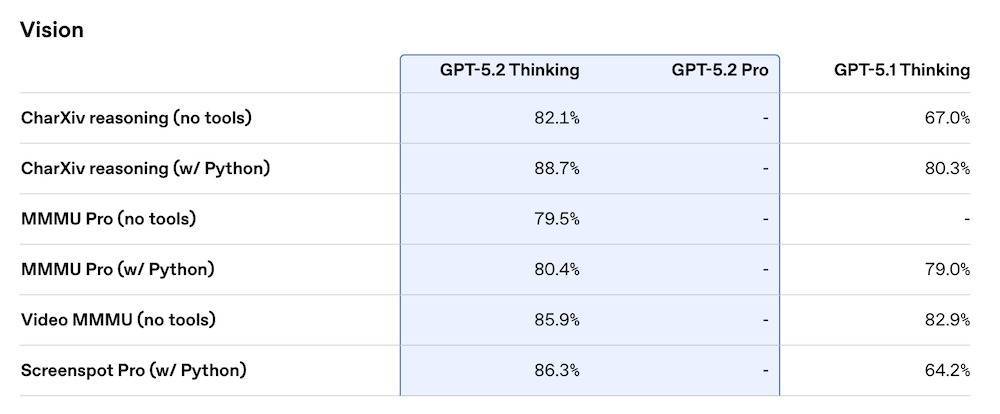
▲图源:OpenAI官方博客
四、微软全家桶同步升级,GPT-5.2成为新一代“生产力模型”随着GPT-5.2发布,微软董事长兼CEO Satya Nadella也在社交平台X平台上宣布,GPT-5.2将全面进入Microsoft 365 Copilot、GitHub Copilot与Foundry等产品体系,并作为新的“默认推理模型”服务更多工作流场景。
在Microsoft 365 Copilot中,用户已经可以通过模型选择器启用GPT-5.2,用于会议记录分析、文档推理、市场研究与战略规划等高复杂度任务。Nadella称,将模型与用户工作数据结合后,GPT-5.2能够更充分发挥推理优势。
在GitHub Copilot中,GPT-5.2适用于长上下文推理与复杂代码库审查,重点覆盖跨文件关系分析、依赖追踪与重构建议等工程类使用场景。
此外,GPT-5.2还同步进入Microsoft Foundry与Copilot Studio,开发者可在构建自动化流程、企业内部Agent或自主开发时直接调用GPT-5.2模型。面向消费者端的Copilot也将随后启动分阶段更新,逐步替换当前版本。
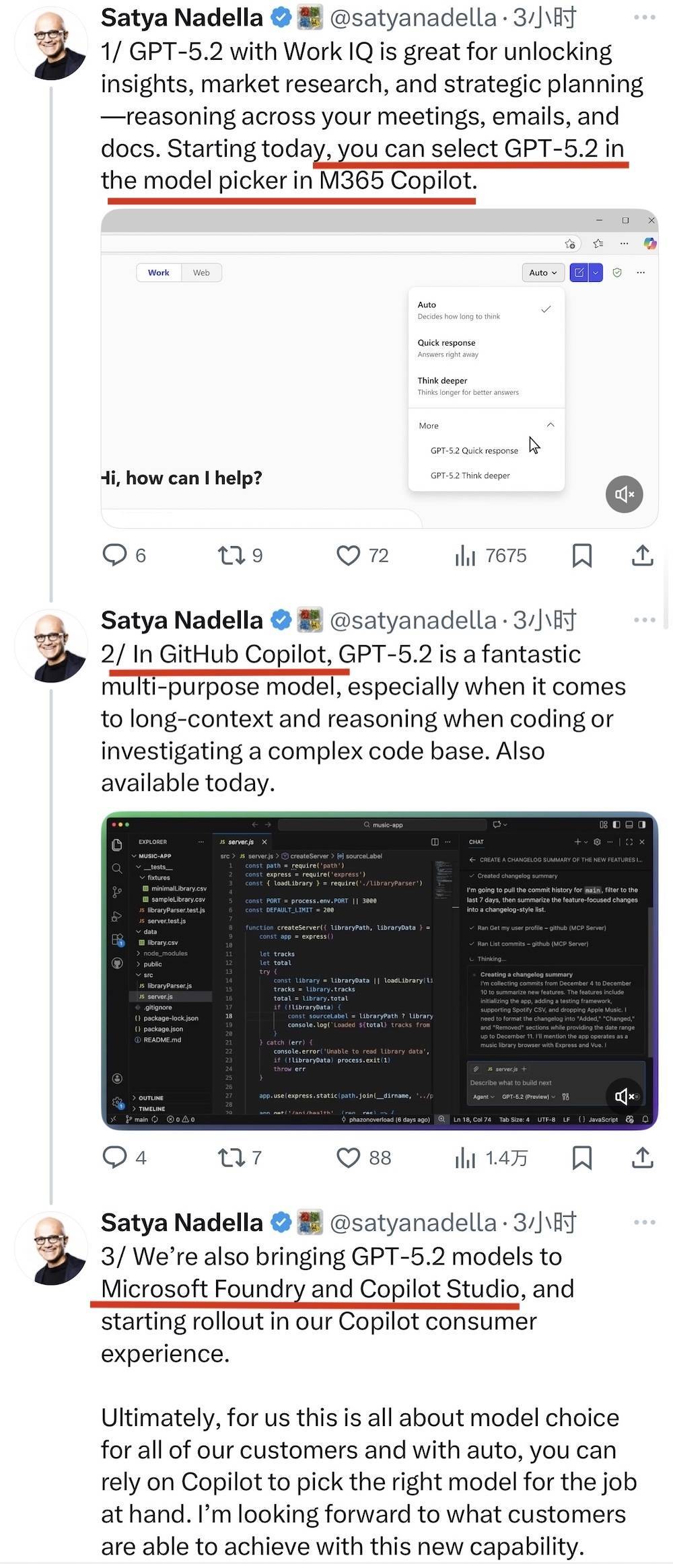
▲图源:X平台
从微软生态的覆盖面来看,GPT-5.2已被定位为“默认生产力模型”,在不同产品线之间以自动模型选择的方式服务更广泛的开发、写作与分析任务。
此外,顶流AI编程助手Cursor也已第一时间火速上线GPT-5.2,并同步沿用OpenAI官方API价格。
▲图源:Cursor
结语:GPT-5.2的能力边界正向“稳定、实用”收拢从多项公开基准测试到Arena针对Web应用端到端能力的评测结果,GPT-5.2展现出的整体能力向稳定可用和任务完成度方向收拢。
随着Instant、Thinking与Pro组成的多档能力体系的开放,GPT-5.2在不同工作流中被切分为更清晰的使用场景。而在微软生态中的全面接入,也进一步强化了这一变化的方向。无论是在M365 Copilot中承担跨文档推理,还是在GitHub Copilot中处理长上下文代码链路,GPT-5.2都开始参与到更高频、更具体的任务流程中。
除了推出面向专业工作和智能体的前沿模型外,OpenAI还宣布已经与迪士尼达成授权协议全国十大配资,允许Sora 2用户在生成并分享的图片中使用迪士尼角色。迪士尼将向OpenAI投资10亿美元(约合人民币71亿元),并拥有未来增持股份的选择权。
顺阳配资提示:文章来自网络,不代表本站观点。
相关文章



沪深京指数
热点资讯